


In the world of programming, multitasking has become a crucial aspect of building efficient and responsive applications. Whether you’re dealing with large-scale data processing, handling multiple user requests, or performing time-consuming I/O operations, doing everything in a single thread can be slow and inefficient. This is where multithreading comes into play.
In Python, multithreading allows for concurrent execution of tasks, enabling your application to handle multiple operations simultaneously. While Python’s Global Interpreter Lock (GIL) imposes some restrictions on CPU-bound tasks, multithreading is still highly beneficial for I/O-bound operations, such as network requests or file handling.
In this article, we’ll explore how multithreading works in Python, how to implement it using the threading module, and when it’s best to use multithreading to improve your program’s performance. Whether you're building a multi-threaded Python application or simply looking to enhance your code with some concurrency, this guide will help you get started.
Also Read: Everything You Need To Know About Optimizers in Deep Learning
What is Multithreading?
Multithreading is a programming technique where multiple threads, or smaller units of a process, run concurrently within a single program. This allows different tasks to be executed simultaneously, making the program more efficient and responsive. Think of it like having multiple workers doing different jobs at the same time, rather than one worker doing everything sequentially.
In Python, multithreading allows for multiple threads to execute within a single process. Each thread runs independently, but all threads share the same memory space. This is particularly useful for I/O-bound operations, where your program spends a lot of time waiting for external resources like reading from a file, making network requests, or interacting with a database.
Multithreading vs Multiprocessing
While multithreading allows multiple threads to share the same memory space, multiprocessing involves running multiple independent processes, each with its own memory space. Here’s the key difference:
- Multithreading: Best suited for I/O-bound tasks, as it allows tasks like reading files, making API calls, or handling user input to run concurrently. However, Python’s Global Interpreter Lock (GIL) means that only one thread can execute Python bytecode at a time. This limits the performance benefits for CPU-bound tasks.
- Multiprocessing: Each process runs in its own memory space and can execute independently of others, making it ideal for CPU-bound tasks like complex calculations or data processing. Because each process is independent, they don’t share memory, avoiding issues like race conditions.
In short, multithreading is great for tasks that are waiting for external resources (I/O-bound), while multiprocessing excels with tasks that require heavy computation (CPU-bound).
How Multithreading Works in Python
Python’s multithreading capabilities are primarily provided through the built-in threading module. While Python supports threading, it's important to understand the behavior of threads within the Python runtime, especially due to the Global Interpreter Lock (GIL).
Understanding the Global Interpreter Lock (GIL)
The Global Interpreter Lock (GIL) is a mechanism that prevents multiple native threads from executing Python bytecodes simultaneously in a single process. It essentially ensures that only one thread executes Python code at a time. This can create a bottleneck in programs that are CPU-bound, such as those performing complex calculations or data processing.
However, the GIL doesn’t prevent multiple threads from running at once when the program is waiting for external resources like files or network responses. This makes multithreading in Python ideal for I/O-bound tasks, where threads spend most of their time waiting for input/output operations to complete.
Thread Lifecycle
A thread in Python follows a simple lifecycle:
- Creation: A thread is created using the Thread class from the threading module, which specifies the target function that the thread will execute.
- Start: The start() method is called on the thread to begin its execution. At this point, the thread is scheduled by the Python interpreter to run concurrently with other threads.
- Join: After starting a thread, you often need to wait for it to complete using the join() method. This blocks the main thread until the target thread has finished executing.
- Termination: Once the thread has completed its task, it is terminated automatically.
Even though Python uses the GIL, multithreading can still be quite useful, especially for I/O-bound tasks like making web requests or handling file operations concurrently.

When Multithreading is Useful in Python
Multithreading is especially beneficial when dealing with I/O-bound tasks, where the program spends a lot of time waiting for external operations. Some common use cases include:
- Network operations: Making API calls, downloading files, or processing multiple user requests.
- File handling: Reading or writing to multiple files at once, such as in a large-scale data processing application.
- Web scraping: Scraping data from multiple websites concurrently, instead of making one request at a time.
In these scenarios, multithreading allows your program to stay responsive and efficient, as threads can work concurrently on these waiting tasks.
Also Read: A Beginner’s Guide to Recurrent Neural Networks (RNN) in Deep Learning
Python’s threading Module
The threading module is part of Python's standard library and provides a simple way to work with threads. It offers various classes and methods to create, manage, and synchronize threads. Let's explore the most important components of the threading module.
Key Components of the threading Module
- Thread Class: The Thread class is the core of the threading module. Each thread is an instance of this class.
- target: The function that the thread will execute.
- args: The arguments passed to the target function.
- target: The function that the thread will execute.
- start(): This method is used to start the thread. It triggers the thread to begin executing its target function.
- join(): This method is called to make the main program wait for the thread to finish its task. It ensures that the main program only continues once the thread has completed its execution.
- active_count(): Returns the number of threads currently alive (running or waiting).
- current_thread(): Returns the current thread object (the one executing the code).
- Lock: A synchronization primitive to prevent data corruption when multiple threads access shared resources.
Creating and Running Threads
To use threads in Python, you first need to define the target function that each thread will execute. Then, you create Thread objects and start them. Here's a simple example:

In this example, we define the function print_numbers() that prints numbers from 0 to 4. We then create a thread to run this function and start the thread with thread.start(). Finally, thread.join() is called to ensure the main thread waits until the new thread completes before it moves forward.
Multithreading in Python Example: Simulating I/O Bound Tasks
Let’s take a more practical example where we simulate multiple I/O tasks, like downloading files (which we'll simulate using sleep()):

In this multithreading example, we simulate downloading two files. The download_file() function takes a name and a delay (simulating the time taken to download a file). Two threads are created to simulate the concurrent downloading of these files.
The time.sleep() function mimics the wait for I/O operations like file downloads or network requests. While one thread is waiting, the other can continue its execution, making this a classic use case for multithreading.
Python Multi Threaded Applications: When to Use It
Multithreading is especially beneficial when your tasks are I/O-bound. Some examples include:
- Web scraping: When scraping data from multiple pages or websites, multithreading can allow you to fetch content concurrently, significantly improving performance.
- File processing: If you're dealing with large datasets and need to read or write to multiple files at once, multithreading can help process files in parallel.
- Networking: When you need to make multiple network requests or handle multiple client connections simultaneously, multithreading can improve responsiveness.
However, it's important to note that multithreading is not a solution for CPU-bound tasks. For such cases, consider using the multiprocessing module, which can bypass the GIL by running separate processes.
Also Read: What is Gradient Descent in Deep Learning? A Beginner-Friendly Guide
Best Practices for Using Multithreading in Python
While multithreading can provide significant performance improvements for I/O-bound tasks, there are some best practices and considerations you should keep in mind to ensure your program is efficient, safe, and easy to maintain.
1. Avoid Shared State When Possible
One of the most common pitfalls when working with threads is shared state—when multiple threads access and modify the same data. This can lead to race conditions, where the program's behavior becomes unpredictable due to threads competing for access to the shared data.
To prevent race conditions:
- Use locks: If threads need to modify shared data, use the Lock object from the threading module to synchronize access.

- Immutable data structures: When possible, use data structures that cannot be changed (e.g., tuples or strings) to avoid modifying shared data.
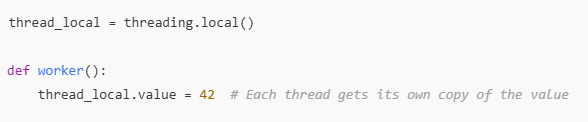
- Thread-local storage: If each thread needs to have its own copy of a resource (e.g., a variable), use threading.local() to create thread-local storage that keeps the data separate for each thread.
2. Use Thread Pools for Managing Multiple Threads
When your program needs to handle a large number of threads (e.g., for web scraping or making multiple network requests), manually creating and managing threads can become cumbersome. Instead, you can use a thread pool to manage a pool of threads that can execute tasks concurrently.
Python provides a ThreadPoolExecutor class in the concurrent.futures module, which abstracts thread management and simplifies the process of running tasks in parallel.

This approach helps you avoid manually creating and joining threads, which can improve readability and scalability.
3. Handle Exceptions in Threads
Since threads run independently, exceptions raised within one thread won’t automatically propagate to the main thread. If a thread raises an exception, the main thread might not be aware of it, leading to silent failures.
To handle exceptions properly, you can use try-except blocks within the thread’s target function, or capture exceptions using the ThreadPoolExecutor:

This ensures that even if an error occurs, it will be properly handled and logged.
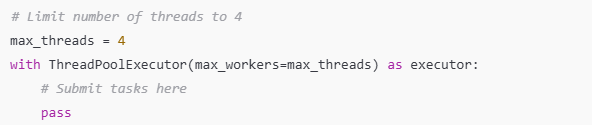
4. Limit the Number of Threads
Creating too many threads can overwhelm the system and lead to excessive context switching, which can degrade performance. Instead of spawning an unbounded number of threads, it's a good practice to limit the number of concurrent threads to a reasonable number.
Use a thread pool, or manually manage the number of threads based on the system's available resources. For example, you might decide to limit the maximum number of threads based on the hardware's capabilities or the nature of the task.
5. Thread Synchronization
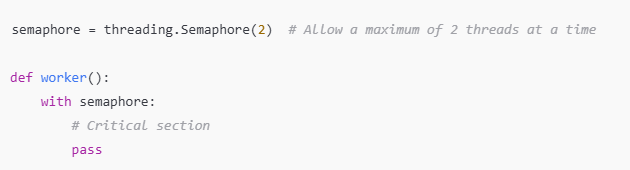
When multiple threads access shared resources or data, thread synchronization becomes crucial. Besides using locks, other synchronization techniques like semaphores, events, and conditions can help coordinate the behavior of threads.
Semaphore: Useful when you want to limit the number of threads accessing a resource.
Event: A way to signal one or more threads to continue execution. It’s often used when you need threads to wait for a specific event to happen.

6. Gracefully Handle Thread Termination
Ensure that threads terminate gracefully by using join() to wait for threads to complete before exiting the program. This helps avoid abrupt terminations that can lead to resource leaks or inconsistent states.

Also Read: Common Deep Learning Interview Questions and How to Answer Them
Conclusion
Multithreading in Python is a powerful tool for making your programs more efficient, especially when dealing with I/O-bound tasks. While it can be complex and challenging to work with, understanding key concepts like the Global Interpreter Lock (GIL), thread synchronization, and using the right tools like ThreadPoolExecutor will help you harness its full potential.
By following best practices such as managing shared state, handling exceptions, and controlling the number of threads, you can build scalable and efficient multi-threaded Python applications that can handle multiple tasks concurrently without running into common pitfalls.
So whether you're working on network applications, file handling, or other I/O-bound operations, multithreading can significantly enhance your program's performance and responsiveness.
Ready to transform your AI career? Join our expert-led courses at SkillCamper today and start your journey to success. Sign up now to gain in-demand skills from industry professionals. If you're a beginner, take the first step toward mastering Python! Check out this Full Stack Computer Vision Career Path- Beginner to get started with the basics and advance to complex topics at your own pace.
To stay updated with latest trends and technologies, to prepare specifically for interviews, make sure to read our detailed blogs:
How to Become a Data Analyst: A Step-by-Step Guide
How Business Intelligence Can Transform Your Business Operations
.jpeg)


.jpeg)









.avif)

Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra.