


Deep learning has emerged as a transformative technology, powering innovations in areas like computer vision, natural language processing, autonomous systems, and healthcare. With their ability to learn complex patterns from massive datasets, deep learning models have achieved remarkable success across industries. However, one major challenge persists — overfitting.
When a model becomes too specialized in learning from the training data, it can perform poorly on new, unseen data, leading to unreliable and unstable results. This is where regularization in deep learning plays a crucial role.
Regularization techniques are essential tools that help deep learning models generalize better by preventing them from simply memorizing the training data. In this article, we’ll explore what is regularization in deep learning, why it’s important, and the most widely used regularization techniques in deep learning that every practitioner should know.
What is Regularization in Deep Learning?
In deep learning, regularization refers to a set of techniques used to prevent overfitting by reducing the model's complexity during training. The goal of regularization is to ensure that the model does not memorize the training data but instead learns generalizable patterns that can perform well on new, unseen data.
Without regularization, deep learning models with a large number of parameters can become too flexible, capturing noise or irrelevant patterns in the training data. This leads to poor generalization when the model is applied to real-world data. Regularization essentially adds a penalty to the loss function to discourage the model from overfitting.
By introducing constraints or modifications to the training process, regularization forces the model to strike a balance between fitting the data well and maintaining simplicity, thus improving its ability to generalize. In simple terms, regularization helps make models robust and reliable in real-world applications, where the input data is often noisy or different from the training set.
In the following sections, we’ll explore why overfitting happens and dive into the various techniques used to regularize deep learning models.
Also Read: Common Deep Learning Interview Questions and How to Answer Them
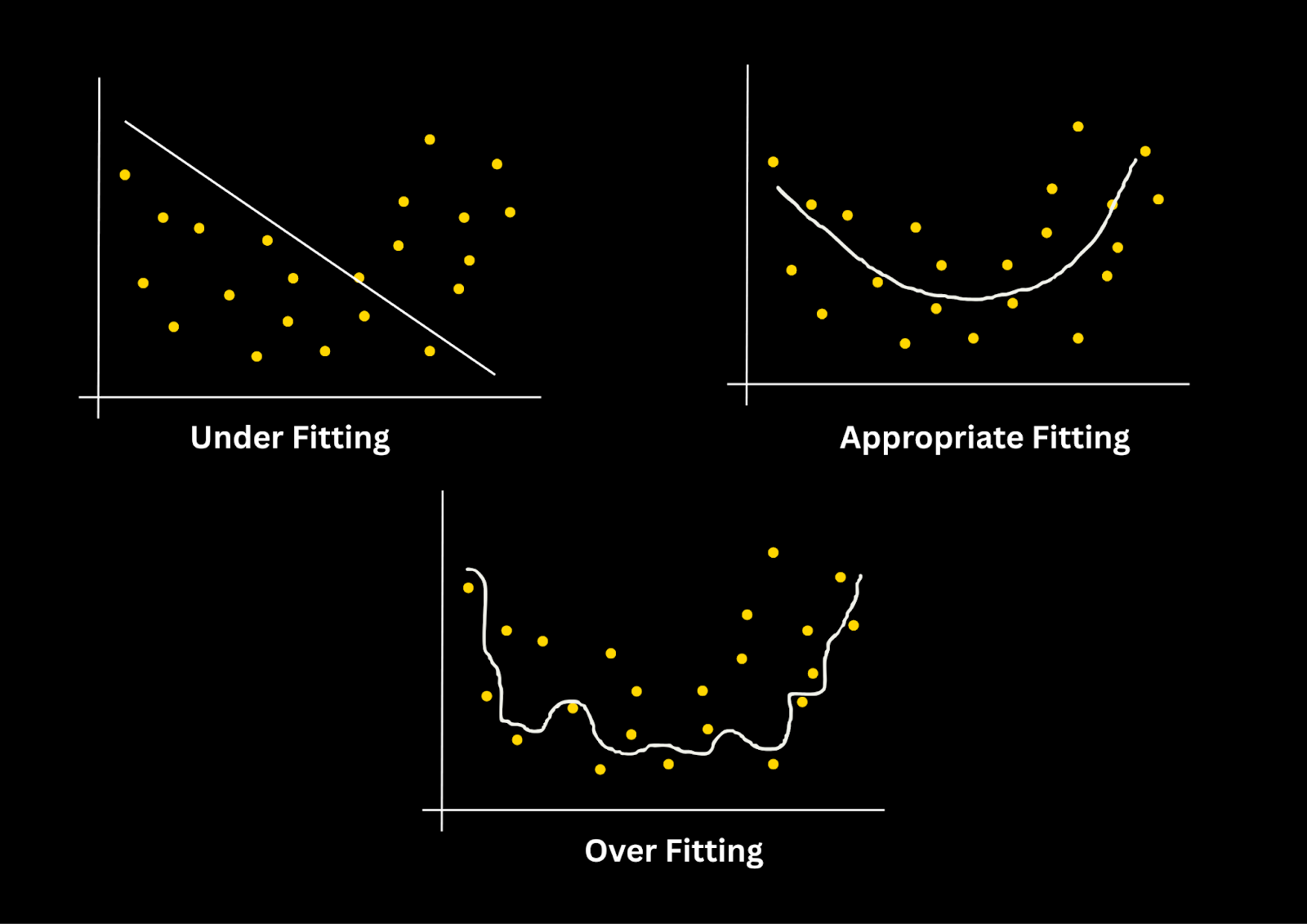
Why Overfitting Happens in Deep Learning
Overfitting is a common challenge when training deep learning models. It occurs when the model becomes too complex and starts to "memorize" the training data rather than learning to generalize to new, unseen data. This happens because deep learning models are capable of fitting even the slightest variations in the training dataset, including noise and irrelevant patterns, leading to poor performance on validation or test data.
Factors Leading to Overfitting
- High Model Complexity: Deep learning models, especially those with many layers or parameters, have immense capacity to learn. While this is a strength, it can also make them overly flexible. The model might learn not only the underlying patterns but also the noise in the data, resulting in a model that performs well on training data but poorly on new data.
- Insufficient Training Data: When there is not enough data to train a model effectively, the model may end up fitting the few available examples too closely. It learns idiosyncrasies specific to the training data, which don’t generalize to new data points.
- Lack of Noise Handling: Training data is rarely perfect. It often contains noisy or irrelevant features. Without regularization, a model may give undue importance to these noisy features, leading to overfitting.
Bias-Variance Tradeoff
Overfitting is closely related to the bias-variance tradeoff, which is a fundamental concept in machine learning:
- Bias refers to errors introduced by overly simplistic models that can't capture the complexity of the data (underfitting).
- Variance refers to the model’s sensitivity to small fluctuations in the training set (overfitting).
Regularization techniques aim to reduce variance without significantly increasing bias, allowing the model to maintain flexibility while avoiding excessive complexity.
By applying regularization, we ensure that the model maintains a balanced tradeoff between bias and variance, ultimately improving its ability to generalize and perform well on unseen data.
Popular Regularization Techniques in Deep Learning
Now that we've established the importance of regularization, let's explore the regularization techniques in deep learning that are commonly used to combat overfitting. These techniques help to constrain the model’s complexity, ensuring that it generalizes well to new, unseen data.
Also Read: Everything You Need To Know About Optimizers in Deep Learning
1. L1 and L2 Regularization (Weight Decay)
L1 and L2 regularization are the most widely used techniques for penalizing large weights in a model, helping to reduce its complexity.
- L1 Regularization adds the absolute value of the model's weights to the loss function, encouraging sparsity. This means that L1 regularization can drive some weights to exactly zero, effectively performing feature selection.
Formula (L1 Regularization):

- L2 Regularization (also known as weight decay) adds the squared values of the weights to the loss function, promoting smaller weights overall.
Formula (L2 Regularization):
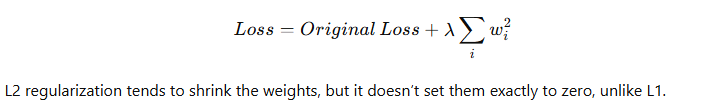
Both techniques can be used together, often referred to as elastic net regularization, combining the benefits of both L1 and L2.
2. Dropout
Dropout is a regularization technique that randomly "drops" (sets to zero) a fraction of neurons during each training step. This prevents the network from becoming overly reliant on specific neurons, forcing it to learn redundant representations and thereby reducing overfitting.
- During training, dropout randomly disables a percentage (e.g., 20% to 50%) of neurons in each layer.
- It acts like an ensemble of different networks since each forward pass uses a different subset of the network.
Dropout is particularly useful in very deep networks and has become a standard technique for many types of neural networks, especially convolutional and fully connected layers.
3. Early Stopping
Early stopping is a simple yet effective regularization technique. It involves monitoring the model’s performance on a validation dataset during training and stopping the training process as soon as the performance starts to degrade (indicating overfitting).
- The model is trained for a certain number of epochs, but we stop as soon as the validation loss no longer improves.
- This prevents the model from continuing to fit noise in the training data once it has already learned the main patterns.
Early stopping is widely used in practice and can significantly reduce training time, as it stops unnecessary training cycles.
4. Data Augmentation
Data augmentation is a technique primarily used in computer vision tasks. It artificially increases the size of the training set by applying random transformations to the input data, such as:
- Rotation
- Flipping
- Scaling
- Cropping
- Color shifting
By presenting the model with slightly altered versions of the same images, data augmentation forces the model to focus on the essential features (like shape or structure), rather than memorizing specific details of the training set. This is a particularly powerful technique for small datasets, as it allows the model to generalize better.
5. Batch Normalization
Although primarily used for improving the training speed and stability of deep neural networks, batch normalization also acts as a regularizer. It works by normalizing the output of each layer in a mini-batch, ensuring that the activations have zero mean and unit variance. This has several effects:
- It reduces internal covariate shift, improving training efficiency.
- It introduces some noise to the network, helping it generalize better.
While not designed specifically as a regularization technique, the secondary regularizing effect of batch normalization is often enough to reduce the need for other forms of regularization.
6. Other Techniques
- Label Smoothing: In tasks like classification, label smoothing softens the hard labels (e.g., instead of a binary label [0, 1], use [0.1, 0.9]). This prevents the model from becoming overly confident in its predictions, leading to better generalization.
- Stochastic Depth: A technique mainly used in deep residual networks where, during training, certain layers are randomly skipped. This prevents the model from becoming too reliant on deep network layers and encourages robustness.
Also Read: What is Gradient Descent in Deep Learning? A Beginner-Friendly Guide
How to Choose the Right Regularization Technique
Selecting the appropriate regularization technique in deep learning can depend on several factors, including the model architecture, the size and nature of the dataset, and the specific task. Each regularization method has its strengths and is suitable for different use cases. Here’s how you can approach choosing the right regularization technique for your model:
1. Model Complexity
- Deep Neural Networks (DNNs) with many layers are particularly prone to overfitting due to their high capacity to learn complex patterns. For such models, techniques like L2 regularization (weight decay), dropout, and early stopping are commonly employed.
- If the model has many parameters and is prone to overfitting, L2 regularization can help prevent the weights from growing too large, while dropout can reduce the model’s reliance on specific neurons.
2. Dataset Size
- For small datasets, data augmentation and early stopping are essential regularization methods. Data augmentation artificially increases the training set size by generating more diverse data, helping the model generalize better. Early stopping prevents the model from continuing to train once it starts memorizing the small dataset.
- For large datasets, L2 regularization and batch normalization are often sufficient. These techniques help maintain generalization without needing additional data augmentation. Dropout, however, can still be useful to reduce model overfitting even in large datasets.
3. Task Type
- For image-related tasks (e.g., classification, object detection), data augmentation is highly effective. Since images often have spatial invariances (such as rotations, flips, or scaling), augmenting data with these transformations forces the model to focus on meaningful patterns, like edges and shapes, instead of specific image details.
- For sequential tasks (e.g., language modeling, time series forecasting), dropout and L2 regularization work well. In sequence-based tasks, it’s crucial to avoid overfitting on small fluctuations, and dropout helps ensure that the model doesn’t become overly reliant on any single temporal feature.
4. Overfitting vs Underfitting
- If the model is underfitting (performing poorly on both the training and validation datasets), it may indicate that the regularization is too strong, or the model is too simple. In this case, you may want to reduce the regularization strength or increase model complexity (e.g., adding more layers or units).
- If the model is overfitting (performing well on the training data but poorly on the validation/test data), it’s a signal that you need to increase the regularization or improve the generalization capacity of your model.
5. Computational Resources and Time
Some regularization techniques may require more computational resources or longer training times:
- Dropout can be computationally expensive during training because it forces the model to train many different sub-networks. However, it can be highly effective in preventing overfitting.
- Early stopping is relatively inexpensive and simple to implement, as it only requires monitoring the validation performance during training.
- Batch normalization can add overhead due to the need for computing statistics over mini-batches but can significantly improve the speed of convergence and reduce the need for other regularization methods.
Best Practices for Regularization in Deep Learning
Choosing and implementing the right regularization techniques can greatly enhance your model's performance. However, the effectiveness of regularization depends not only on the technique itself but also on how it is applied. Here are some best practices for regularization:
1. Start Simple and Experiment Gradually
When you begin training a model, it’s essential to start with a basic architecture and regularization approach. For example, you can begin with L2 regularization and early stopping. Once you have baseline performance, you can experiment with more complex techniques like dropout or data augmentation.
- It’s crucial not to overload the model with regularization methods too early. Gradually introduce additional techniques to see how they affect performance.
2. Monitor Validation Performance Regularly
Regularization’s primary goal is to improve generalization to unseen data. Hence, always track validation performance during training. Techniques like early stopping and dropout can prevent the model from becoming too tuned to the training data, but it’s important to verify that the model’s performance improves on the validation dataset as well.
- Keep an eye on the training vs. validation loss. A large gap between these can indicate overfitting, signaling the need for more regularization.
3. Use Cross-Validation
To better understand how your model will generalize to unseen data, use cross-validation (especially for smaller datasets). Cross-validation splits your dataset into multiple subsets, training the model on some subsets and validating it on others. This helps to detect overfitting across different subsets of the data and gives a more robust estimate of model performance.
4. Adjust Regularization Strength (Hyperparameter Tuning)
The strength of regularization is controlled by hyperparameters (e.g., the λ in L1 and L2 regularization). Hyperparameter tuning is essential for finding the right balance between underfitting and overfitting. You can perform grid search or random search to tune the regularization strength and other model parameters effectively.
- Start with moderate values and experiment with increasing or decreasing the regularization strength based on performance.
5. Combine Multiple Regularization Techniques
In practice, using a combination of regularization techniques often yields the best results. For instance, using L2 regularization for weight decay, along with dropout for reducing neuron reliance, is a common and effective approach. Batch normalization can also be used in conjunction with other regularizers to speed up convergence and improve generalization.
- Be mindful not to overcomplicate your regularization setup. Test combinations of methods and assess their impact on performance.
6. Regularize During Pre-training or Fine-tuning
When working with pre-trained models (e.g., transfer learning), regularization can help fine-tune the model to the specific task. While pre-trained models are already well-regularized to some extent, adding light dropout or L2 regularization can help when fine-tuning the model on a new dataset.
Also Read: A Beginner’s Guide to Recurrent Neural Networks (RNN) in Deep Learning
Conclusion
In summary, regularization in deep learning is a critical concept for ensuring that models generalize well to new data. By using techniques like L2 regularization, dropout, early stopping, and data augmentation, you can significantly reduce overfitting and improve your model’s performance.
Remember, there is no one-size-fits-all solution. The key to effective regularization lies in understanding the specific needs of your model, dataset, and task. Experimenting with different techniques, monitoring performance closely, and tuning regularization strength will help you build robust models that excel in real-world applications.
By applying the right regularization techniques, you’ll be able to train deep learning models that are not only accurate but also reliable and scalable in production.
Ready to transform your AI career? Join our expert-led courses at SkillCamper today and start your journey to success. Sign up now to gain in-demand skills from industry professionals. If you're a beginner, take the first step toward mastering Python! Check out this Full Stack Computer Vision Career Path- Beginner to get started with the basics and advance to complex topics at your own pace.
To stay updated with latest trends and technologies, to prepare specifically for interviews, make sure to read our detailed blogs:
How to Become a Data Analyst: A Step-by-Step Guide
How Business Intelligence Can Transform Your Business Operations
.jpeg)


.jpeg)









.avif)

Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse varius enim in eros elementum tristique. Duis cursus, mi quis viverra.